Vol.1 デジタル変革のための情報基盤センターの役割
北海道大学情報基盤センターの学際大規模計算機システムは、全国の大学や研究機関による学術研究を推進する計算リソースとして大いに利用されています。今回は2022年10月より情報基盤センターのURAとして兼務している私が、棟朝 雅晴 情報基盤センター長に、これまでのご研究の内容や北海道大学アカデミッククラウド導入の経緯、デジタル変革(DX)の推進などについてお話を伺います。(聞き手:URAステーション 佐藤 崇)


─ 本日は、どうぞよろしくお願いいたします。ご存じのとおりほぼ素人なので、わかりづらい質問などもあるかもしれませんが、ご容赦ください。
棟朝 よろしくお願いします。
─ まず、先生のご経歴、大学ではどんな研究をされていたかについてお話しいただけますか。
棟朝 私は小樽出身で、高校卒業後に北大に入学しました。長い話になるかもしれませんが、当時の理I系という、物理・数学系に入りまして、工学部の電気工学科を卒業しました。配属されたのは情報学の研究室でした。その当時は電気工学科と情報工学科が同じカリキュラムだったので、所属は電気工学科でしたが、研究室配属以降はずっと情報科学関連の研究を続けていました。大学院でも情報工学で博士号を取得しました。
その後、北大の工学部に助手として採用されました。その当時は情報図形科学とも呼ばれていた情報科学の講座です。もともとは情報教育を担当しており、情報科学や情報処理の講義や実習などを担当しておりました。
当時の最初の研究としては、並列分散処理と、いわゆる進化計算(Evolutionary Computation)と呼ばれるもの、それによる最適化の手法などを研究していました。進化計算のうち特に代表的なものは、遺伝的アルゴリズムと呼ばれているものです。その後1年ほど、在外研究で、遺伝的アルゴリズムで有名なイリノイ大学のゴールドバーグ先生(Prof. David E. Goldberg)の研究室に受け入れてもらいました。帰国後は、現在の情報基盤センター(以下本センターという)の前身の一つである、情報メディア教育研究総合センターの助教授として着任しました。着任後は、情報メディアシステム分野で、今で言うELMS(北海道大学の教職員や学生が利用できる教育情報システム)に該当する教育用計算機システムのシステム面の管理運用を担当していました。ですので当時は、教育用計算機システムの面倒を見ながら、研究としては引き続き、進化計算と呼ばれる分野と並列分散処理に関する研究を続けてきました。
─ その後、今のセンターができるのですね。
棟朝 はい。2003年に大型計算機センターと情報メディア教育研究総合センターが統合されて今のセンターができた際には、大規模計算システム研究部門の所属となりました。ここは、現在のスーパーコンピューティング研究部門と、システムデザイン研究部門と関係しますが、いわゆるスパコンや大規模な計算機システムに関わる研究開発を推進するところでした。その後、デジタルコンテンツ研究部門の教授に昇任しまして、さらにシステムデザイン研究部門という新たに立ち上がった部門に異動となり現在に至るというところです。そして、2013年から副センター長を務め、2019年からはセンター長を拝命しております。
─ ありがとうございます。ここから先生のご経歴を紐解いていきたいと思います。まず、大学入学の頃から、こういった情報関係の研究分野を目指したのでしょうか。
棟朝 学生時代は、制御工学に興味がありました。それで、電気工学科を選んだのですが、私の入った頃が1980年代の終わりぐらいですので、ちょうどインターネットのような新しい技術が登場しつつある頃でした。大学院生の頃には、北大にもインターネットが導入され始めていて、当時、研究室にもワークステーションと呼ばれる計算機がありました。それらを使った研究や、さらに博士課程の時には今のスパコンのような並列計算機を使って、負荷分散のアルゴリズムやシステムに関する研究をしていました。もともと電気工学科でしたが、いわゆる計算機の発展に伴って、そちらに興味が湧いてきたというところです。
─ 計算機のどのような点に興味が湧いたのでしょうか。当時の計算機は、今のコンピュータよりもはるかに最先端な存在だったと思います。
棟朝 私が最初に配属された研究室に、先代センター長の髙井 昌彰先生がいらっしゃいました。髙井先生のご指導を受けて、並列分散処理と遺伝的アルゴリズムの研究を始めたのですが、そのきっかけも、たまたま髙井先生が購入された遺伝的アルゴリズムの教科書が大変興味深かったからでした。ちなみに、その教科書を執筆したのが、先ほど申し上げたイリノイ大学のゴールドバーグ先生です。最初に読んで非常に感銘を受けました。つまり、計算機の中で自律的に進化をさせて問題を解いていく、しかも、多様な生物が並列に進化していくのと同じように、大規模な並列分散処理とも親和性が高いという点に非常に興味を覚えました。
修士論文では、並列の遺伝的アルゴリズムという、いわゆる最適化の問題を解く場合に、大規模並列で解決し、そこに生物の進化の考え方を取り入れることを研究していました。初めての国際会議にも、その修士論文の成果で参加しました。その国際会議が開催されていたのが、後に在外研究で行くことになるイリノイ大学だったということも、不思議な縁を感じます。その後、並列計算機の分散処理の最適化に、その進化計算、遺伝的アルゴリズムと機械学習を使う研究をしてきました。
─ 感銘を受けた本の著者の下で研究ができるというのは、すごく夢のある話ですね。
棟朝 そうですね、大変ありがたい話でした。
─「並列分散処理」が先生の経歴の中にキーワードとして入っていますね。
棟朝 はい。並列分散処理ということで、先ほどのいわゆる負荷分散とか、あとは博士号をとった直後ぐらいは、例えばネットワークの経路制御のような、インターネット上での分散処理の研究をしていました。さらには、こちらのセンターに異動してからは、いわゆるクラウドコンピューティングですね。こちらにつきましては2011年、今から10年以上前ですけれども、北大アカデミッククラウドという学術向けのクラウドシステムの先駆けとなるシステム導入を私が担当しまして、設計から調達、そしてサービス開始にまで漕ぎ着けました。いわゆる並列分散処理の流れでは、クラウドコンピューティングに関する研究開発を進め、並行して業務としても、北大のクラウドをサービスとして提供することを、2011年から始めたことになります。大学関係のクラウドとしては最初の事例でしたし、民間の方とも一緒に進めさせていただいたので、その後この活動は、クラウド関係の業界などからも注目されることになりました。
─ 北大が日本の中でも口火を切った存在ということですね。
棟朝 似たようなシステムは他の大学にもありましたが、いわゆるクラウドのミドルウェアといって、本格的なクラウド管理ソフトウェアを導入して、クリック一つでサーバやインフラが使える環境を作ったのは、北大が先駆けでした。実はこれも、人との出会いがきっかけでした。今は、オープンソースになっていますが、当時アメリカのCloud.com社というベンチャー企業が作っていたCloudStack(クラウドスタック)というクラウド管理のソフトウェアがありまして、その会社の社長であるSheng Liang(シェン・リャン)氏と国際会議でお会いして話が盛り上がり、これを導入することに決めました。通常、こういった最先端のソフトウェアを導入するのは、なかなかリスクが大きいのですけれども。
─ そうですよね、先例などがない状態ですし。
棟朝 スパコンとクラウドシステムを同時に導入することになりましたので、最終的に入札の結果、日立製作所との協業となりました。業者の方にとってもかなりハイリスクで大変だったと思うのですが、一緒に奮闘してサービス開始に漕ぎ着けたのは、今振り返っても良い思い出です。本当に動くのだろうかと、ドキドキしながら対応していました。
─ 当時から、そこに先生が目を付けた利点と言いますか、これはとても役に立つと思った理由などはありますか。
棟朝 当時はサーバの仮想化といって、集約化するところまではある程度できていました。今でいうアマゾンウェブサービスという、クリック1つでサーバにアクセスできて便利につかえる仕組みは始まっていましたが、それと同じことを大学内でできればおもしろいだろうなというところが、大きなモチベーションでした。もちろん、合理的理由としても、そのような集約化をするとかなりのコスト削減になるという目論みもありました。そういった、個人的におもしろいという感覚と、大学にとってのコスト削減や効率化には絶対必要だという強い確信から、リスクは高いけれどもやってみようということになりました。当時は、上司の髙井先生にもご理解いただいて、一任してくださったのは大変ありがたいことだと思っています。関係したベンダーや技術職員の方にも全面的に協力いただいて完成させることができ、非常に感謝しているところです。
─ 大変な困難が想像できます。今でもそのシステムは北大の特色であって、他の大学にはないものなのでしょうか。
棟朝 もちろん、クラウド自体は一般的になっていますが、その後、システム更新が一度ありまして、今は、オープンスタックと呼ばれるものになっています。2回目の更新の時には、私と同じシステムデザイン研究部門で若手の杉木 章義准教授に対応していただいたのですけれども、本格的なクラウドを運用するのは非常に大変です。当時、私の予想としては、ほかの大学も北大に倣ってどんどん導入するかな、と思っていましたが、意外に追従されませんでした。北大の場合は、幸いにも、現場の技術職員の方々にきちんと対応していただけたという点が非常に大きかったのです。 最近では、北大も含めた日本の9大学と2研究所が連携して、mdx(※1)というデータ活用社会創成プラットフォームを立ち上げました。これも、仮想マシンを提供しデータ科学の研究を中心に活用するという点で、実は北大のクラウドとほぼ同じ中身です。この事業には本センターも参画していますが、ここに来てようやくこのような取り組みができるようになってきました。繰り返しになりますが、やはりクラウドを運用するというのは非常に大変なのです。

─ 新しい技術ですから、技術職員も勉強が必要でしょうし、装置はどんどん進歩していきますから、クリアすべきことは山積みですね。クラウド運営の大変さはそのような点にあるのでしょうか。
棟朝 そうです、なかなか手間がかかるというところですね。いわゆるスパコンですと、もちろんそちらも運用は色々と大変なのですが、ログインして、バッチ処理でジョブを投げるという、比較的シンプルな運用になります。クラウドの場合には、システムをつくる人によって、使い方が全然違います。要は、サーバからネットワーク、全て設定してシステムを作っていきますので、個別性が高くなるのです。しかも、手軽に使ってもらうとなると、セキュリティの問題が生じますので、その点はなかなかハードルが高いところです。特に、研究用途の場合には、かなりの手間をかけて、システム化していかなければいけないのです。
─ では、今本センターで使っているシステムを他の大学とも連携させるとなると、同じようなシステムに統一する必要性があるのですか。
棟朝 少なくとも、相互に運用できるような整合性をとって設計、構築していかないといけませんね。
─ ハードルがかなり高そうですね。
棟朝 ですので、現行のシステムでは、各大学と調整をするのは大変でしたので、インタークラウドパッケージといって、東京大学・大阪大学・九州大学と連携するために北大の資源を各機関に設置し、まとめて使ってください、みたいなこともしているのです。
─ なるほど。それは画期的ですね。ちなみに、先の話になってしまいますが、次のシステム構想も、先生の中にはあるのですか。
棟朝 はい、今はセンター長の職におりますので、方針は決めております。現在は、仕様策定委員会で次のシステムについて、検討しております。スパコンの性能拡充に加え、クラウドも最近の流れに合わせたシステムにアップグレードするということで、関係するセンター内の先生方にご検討いただいているところです。そちらは今、調達中ですので、詳細は申し上げられませんが、楽しみにしていただければと思います。
─ 楽しみにしております。
では、少し話を変えて、本センターについてお聞かせください。私は着任まもないため、情報基盤センターと聞いたときに、そこがどういう業務をしているのか、所属されている先生方はどんな研究をしているのかという点が、あまり想像できません。学内にも、スパコンなどに馴染みのない研究者は少なくないと思いますので、所属されている先生方がどのような業務・研究をされているのか、ご説明いただけますでしょうか。
棟朝 本センターには、いくつかの側面があります。
まず、当然ながら学内にあって、学内の情報基盤に関わる研究開発を推進し、その成果を活用し、学内の情報基盤、情報環境を高度化する、という点です。これが一つの大きな役割です。
次に、学際大規模情報基盤共同利用・共同研究拠点(Japan High Performance Computing and Networking: JHPCN)という、全国の研究者が共同で研究を推進する拠点の一角を担うという点です。全国共同利用の研究所、北大にも低温科学研究所とか電子科学研究所などがありますが、当拠点は、複数拠点の研究ネットワークにより構成される「拠点ネットワーク」となっています。東大、京大、阪大など、いわゆる旧帝大に東工大を加えた8大学の連合体で、保有する資源を共同利用・共同研究のために提供しています。 そして、スパコンに関しては、革新的ハイパフォーマンス・コンピューティング・インフラ(High Performance Computing Infrastructure : HPCI)と呼ばれる、富岳をトップとした日本全体の大学や研究機関のスパコンを高速ネットワークで結んで幅広いユーザー層が効率よくスパコンを利用できるよう構築された共用計算環境基盤がありまして、センターのスパコンはその一部でもあるため、この運用を支えるという側面ももっています。
また、先ほど「学内の」と言いましたが、センターには、スーパーコンピューティング、情報ネットワーク、デジタルコンテンツ、メディア教育、システムデザイン、サイバーセキュリティの6つの研究部門があり、大学全体の教育やセキュリティに関わっています。端的にいいますと、情報基盤、情報環境に関わる機能をセンターに集約し、お互いに連携して全学並びに全国の情報基盤に関係する研究開発を積極的に推進するという役割もあります。
他にも、センター内には情報環境推進連携部が設置されています。学内の業務的な情報基盤、例えば、キャンパスネットワークや事務用のクラウド、セキュリティなどに関しては、総長を本部長とする「情報環境推進本部」(※2)の所掌となっていますが、そこに設置されている組織には、本センターの教員が全面的に協力しています。具体的には、私はこの本部内に設置されている「情報化推進室」の室長を兼務していますし、「セキュリティ対策室」の室長は本センター所属教員である南 弘征先生が兼務しており、髙井 昌彰先生、飯田 勝吉先生も参画されています。つまり、本センター所属教員が情報環境推進本部と連携し、本センターにおける研究開発の成果やその知見を生かし、全学の情報化の推進に資する、という役割をも担っているわけです。 さらに、メディア教育研究部門の教員がオープンエデュケーションセンターとの兼務によりELMSの運用において主導的な役割を担っています。
ここまでお話ししたように、研究開発を行う教員が、学内の情報基盤、情報環境を発展させるために、このセンターに集まっている、そしてお互いに相談・連携しながらその知見を生かしている点が、非常に重要だと思っています。
─ 大変よくわかりました。
また、学内に限らず、学外の情報基盤ネットワーク構築というところにも大きく貢献されているのですね。
棟朝 そうですね。例えば、国立情報学研究所が提供しているSINET(Science Information NETwork)という学術情報ネットワークの委員に本センターの先生方が何名か入っていますし、さらにセキュリティの関係の委員会等でも、本センターのセキュリティ担当の先生方が主導的な役割を担っています。北大だけではなくて、全国の学術ネットワーク、スパコンのネットワークでも、本センターの教員が主導的な役割を担っています。
─ なるほど。
ネットワークに関しては、北大はキャンパスがものすごく広いというイメージをみなさんが持っていると思うのですが、そのキャンパス、例えば臨海実験所や演習林もありますし、北海道だけではなく和歌山にもあります。それらはすべて、北大の情報ネットワークの中でつながっているのですか。
棟朝 遠隔地の接続については、本センターで対応しています。昔は地方にはSINETがあまりなかったのですが、最近はSINETのノードが地方にもできつつあります。例えば函館キャンパスは、昔は札幌から回線を引いていましたが、函館にSINETのデータセンターができましたので、函館から引くことができるようになりました。北大は非常に広いので、今後、例えば演習林にセンサーを置くとか、そういったことに対応していくことも重要だと考えています。
─ わかりました。では、ここでお話を変えて、最近よく耳にするDX(デジタルトランスフォーメーション)についてお聞かせください。単語としてはよく聞くのですが、私にとってDXというのは、何がトランスフォーメーションするのか、わからない点が多いのです。その辺りから説明していただけるとうれしいです。
棟朝 「DX」というのは、単に情報だけではなくて、より広い概念だと思っています。DXとはデジタルのDとトランスフォーメーションのXですけれども、デジタルトランスフォーメーションを考えるとき、そのトランスフォーメーション(=変える)という部分がまず鍵になると思います。つまり、今あることを良く変えたい、その「変えたい」のためにDのデジタル技術があるのです。そのため、何かを変えたいとは特に思っていない人や組織には、DXは意味がない、と思っています。まず、トランスフォームをしたいという意志があって、そのトランスフォームのためにデジタル技術を使うことで変革がしやすいということ。Xが先に来てDがある、と思っています。
─ なるほど、意志があるかどうかが大事なのですね。
棟朝 トランスフォームに関して、最近は、強制的にトランスフォームさせられるという例もあります。例えば、コロナ禍で出勤できなくなったり、リモートで業務をせざるを得なくなったりということで、みなさんよくご存じのとおり、ZoomやWebexのような、いわゆる遠隔会議のシステムが普及しました。私などは、Zoomは既に10年以上前、出た当時から使っていました。先ほどの「拠点ネットワーク」ですと、複数大学が参画していますので、テレビ会議が当たり前でした。ただ、トランスフォームについては、そのような新しいデジタル技術があるだけではだめで、みんなが使う状態になって初めてトランスフォームされたということになります。こういったコロナ禍のような社会情勢の変化によって、強制的にトランスフォームされて、技術としてデジタルを利用する、というのが、まず1つの側面としてあります。
こういった強制的なのもありますけれども、やはり、これから特に大事なのは、自分たちでトランスフォームしたいという意志のある人が、デジタル技術をどう活用していくかというところを、現場の方々や業務系の方々も含めて一緒に進めていくことだと思っています。
全体的なDXのイメージというのがこちらの図です。
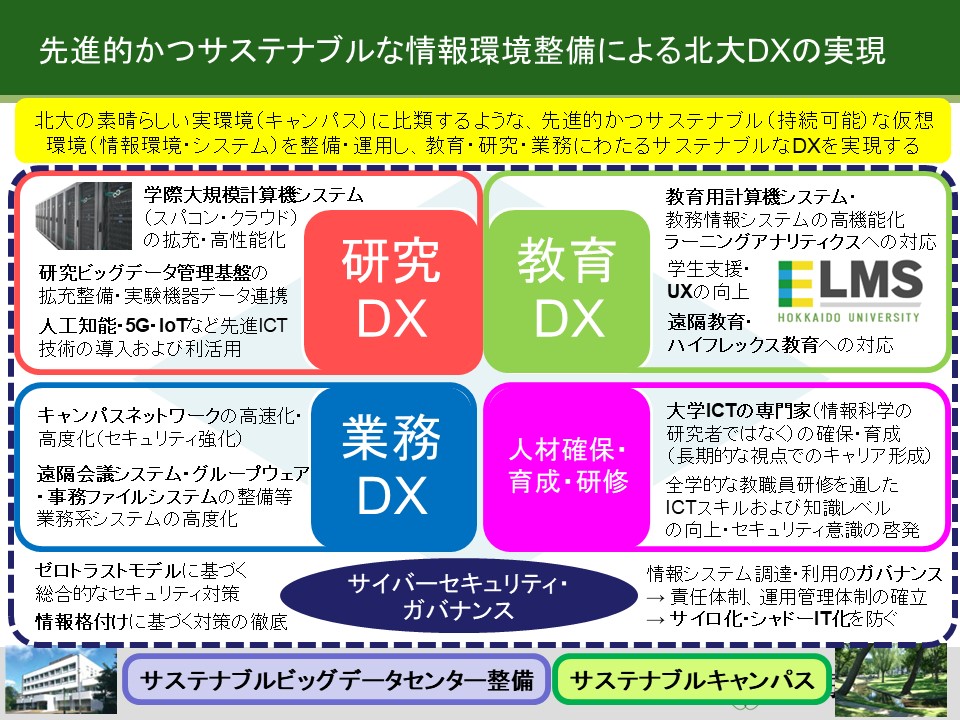
まず、下のレイヤーとして、データセンターなどインフラのレベルから整備していきます。今は日本、世界全体でも、ものすごい勢いでデータセンターが整備されています。DXのデジタル部分には、これがないと始まりません。北大においても、本センター南館の大規模改修をこれから始めていきますが、さらに北館も含めて全体としてデータセンターを整備して、基盤となる下のレイヤーから支えていきたいと考えています。
次のレイヤーとしては、その上にガバナンスやセキュリティと書かせていただきました。言うまでもありませんが、やはりセキュリティは非常に重要です。もちろん、厳しくするといろいろご不便をおかけするところもあるかもしれません。理想的には、できる限り不便をかけず、セキュリティを守るという形でシステム化していくことになります。ここにあるようなゼロトラストモデルを実装し、機微情報をどう守っていくかを考え、あとはいわゆるシャドーITと言いますが、隠れたところで怪しいものを使わないなどのガバナンスも大事になってきます。こういったものがベースにあった上で、教育、研究、業務の3つに関するDXが成り立っていきます。あとはICTに関する人材育成というのも非常に重要になります。本センターだけではできない部分もありますが、支援していきたいと思っています。
特に本センターとしては、いわゆる学際大規模計算機システムと言われるスパコンとクラウド、さらにビッグデータの処理基盤、蓄積基盤、あとは人工知能のような先進的な技術、そういった、特に「研究DX」の部分を中心に支援していくことが期待されていますし、先ほどお話しした学際大規模計算機システムの更新においても、それを意識して、予算の範囲内ではありますけれども、性能向上を図っていくという計画で進めています。
また、「業務DX」に関してもキャンパスネットワークの高度化や、情報環境推進本部が進める今後の情報環境の整備に対して研究開発の成果を展開する、そして「教育DX」に関しても、メディア教育研究分野等がありますので、研究の成果を活用していくというところが、センターの大きな役目になっていると考えています。
そして人材教育については、本センターの一部教員は情報科学院で情報教育に携わっており、他の教育部局とも連携してこれを進めていきたいと思います。
さらには、人材確保そして育成ですね。こちらは喫緊の課題になっており、やはり、ITの基盤を支える人材というのは、日本全体で非常に不足しています。民間でも、インフラエンジニアは全く足りていないのが現状です。もちろん、情報系の卒業生はそれなりにいますが、外国と比べると格段に少ないということで、今、国の政策でも学生を増やそうという動きがあります。言い方は良くないかもしれませんが少し地味な分野ということもあり、例えば人工知能とかの最先端の部分には学生も集まるのですが、インフラの部分にはなかなか集まりません。さらに言うと、大学の情報基盤、学内インフラを支える人材、これは教員だけではなくて、技術職員等も含めてですけれども、そういった方はできる限り確保し、育成していくということが非常に重要な取り組みです。
日本全国どこの大学でも困っていまして、人手が本当に足りないのです。本センターの枠組みよりも、もう少し広い視野で考える必要があります。
─ もともと人材が少ない北海道の中で、さらにIT分野となると、ものすごく絞りこまれるかもしれませんね。
棟朝 そうですね、そこが大変ですね。
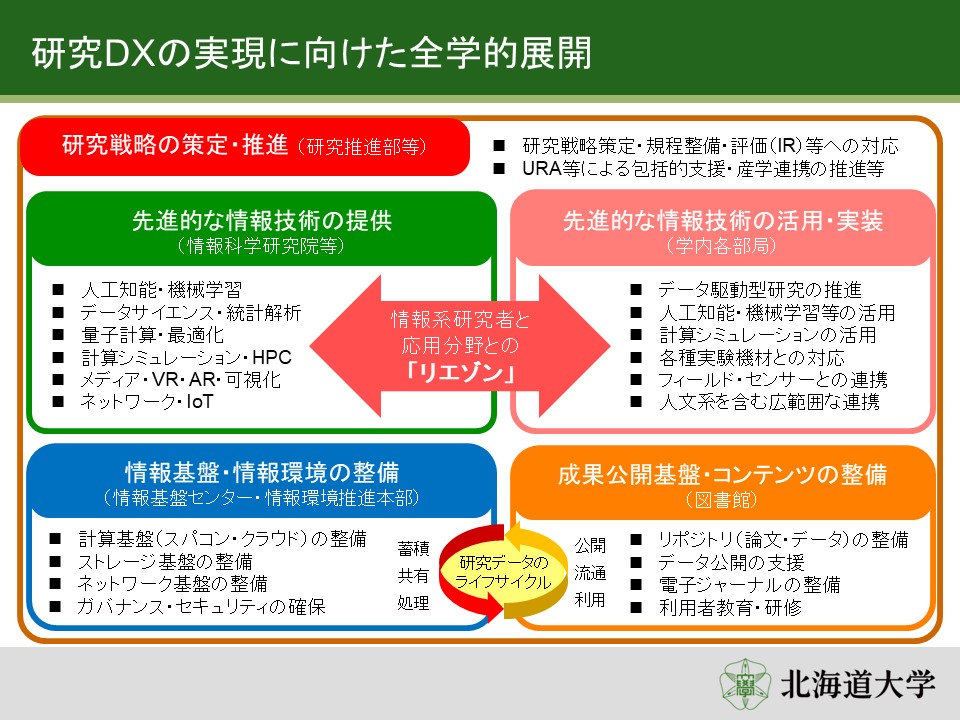
あとは、研究DXの説明に移っていくと、こちらの図にもありますが、いわゆる情報基盤の整備というところは、本センターが、スパコン、クラウド、ストレージ、ネットワーク、ガバナンス、セキュリティといったようなものを担っていますけれども、われわれだけでできるものではなくて、例えば成果の公開に関しては附属図書館、先進的な情報技術そのものであれば情報科学研究院が担っています。もちろん、本センターも、スパコン、いわゆるハイパフォーマンスコンピューティングと呼ばれる分野を中心に機器を提供していますが、実際にそれを使いたい方、学内でニーズがある方とうまくつないでいくことが非常に重要だと考えていますし、URAの方にも今後ご協力いただいて、学内外での共同研究を進めていく必要があります。
─ 私の方でも学内のスパコンに対するニーズ調査を進めておりますが、使い方はもちろん、それを使うことによるメリットをちゃんと理解して、その上で使いたいというような上級者は少ないので、どちらかというとデータはあるけど扱い方がわからないといった初心者からの講習会開催の要望をよく聞きます。これから新しく利用される方を広げて、スパコン人口を増やすためには、そういうところができるといいなと素人ながらに思っていました。
棟朝 まったくおっしゃるとおりだと思います。本センターは、スパコンの活用に関する講習会を頻繁に行っています。特に、新しいシステムを立ち上げた直後には複数回開催していまして、ハンズオンで実際に使ってみる機会を提供しています。ただ問題は、それを全ての分野でやるとなると、人手が足りないという点です。特に、最近ですとデータ駆動型の研究ですね、それぞれの研究分野の方がデータをお持ちですが、これをどうしたらいいのか、長期的にどう保存したらいいのか、どう処理したらいいとか、どう公開したらいいのかという、そこのサポートが決定的に足りていないと思います。
全国的にも状況は同じですが、北大ではシステムとしてはそれなりに揃っています。例えばスパコンで処理もできますし、ストレージもペタバイトクラスの巨大なものが入っております。アーカイブで遠隔サイトに安全にバックアップをとってもいます。また、Nextcloudという、Dropboxのように簡単にデータをやり取りできるものもあります。さらには学認RDM(研究データ管理:Research Data Management)というのがありまして、これは北大だけではなく全国レベルで研究データを研究グループ内で適切に管理するというシステムで、北大でもシングルサインオン(SSO)のアカウントを持っている方であれば、どなたでも使えます。加えて、先ほどお話ししたNextcloudと連携して、大容量の研究データを保存できるものはすでに整備済みです。では、それをどう具体的に活用して研究を進めていくかというところ、先ほどのクラウドもそうですが、きめ細やかにサポートするには非常に手間や人手がかかるので、そこをどう考えるかという点になります。支援体制を拡充していく必要がありますが、人材も少ないのです。
─ 難しいですね。
棟朝 新たな人を雇用しないといけません。例えばグローバルファシリティーセンターの実験機器からデータを吸い上げて、スパコンやクラウドで処理して、リポジトリで公開するといったことを統一的にできるような枠組み、ハードウェアとかネットワークはあるのですけれども、いわゆる人的サポートや、ソフトウェアサポートというところが、課題なのです。この図にある、データフローのガバナンスというのを確保して、使いやすいシステムにしていくこと、これはかなり喫緊の課題でして、最近ですと特に大型の研究資金では、研究のデータにメタデータを振って、きちんと公開・管理をしないといけないというニーズが増えてきていますし、科研でもそういったことを求められています。そういったニーズに、今後対応していく必要があると考えています。
─ そういうシステムは既にできあがっているということですが、現状で、本センターでは利用者に対しての支援はあるでしょうか。
棟朝 基本的には、やはりスパコンとクラウドでのサポートになります。業者によるサポートもありますし、あとは、無料で使えるという支援もしていますね。これは、先ほどの、共同利用・共同研究拠点で公募しているものですね。その他に、本センター独自で公募しているものや、学内向けの人工知能対応先進的計算機システムがあり、公募しています。それらに応募いただいて採択されれば、無料で使えるという支援をしております。
─ 採択は難しいのでしょうか。
棟朝 共同利用・共同研究拠点の公募はそれなりに頑張って応募しないと採択されないというのが実情ですが、ぜひ応募いただきたいと考えています。共同研究としてご応募いただくので、そのメンバーに入ったセンターの教員が、適宜サポートするという枠組みもあります。もちろん、問い合わせに関しては技術職員等が対応いたします。
─ わかりました。今後、スパコンというものは、われわれの研究用としてはもちろんですけれども、一般の方々でも使えるように発展していくものなのでしょうか。
棟朝 スパコンと一言で言いますけれども、例えば今、みなさんお持ちのスマートフォンがありますよね。実は、これは何十年か前のスパコンと性能は同じなのです。ですので、現在スパコンで当たり前になっていることは、20年、30年と経つと、コンシューマーレベルになってくるのです。それだけの計算を、今のスマートフォンはしているということになります。実は、スパコンと言っても縁遠いものではなくて、もちろんスマホのプログラムを組むというのは難しいとは思いますが、活用という意味では、みなさんが身近に使えるようになっていて、研究も支援しているということになります。
スパコンそのものは普通の、いわゆるUNIX/Linuxのマシンですので、そこをわかっていれば使えます。スパコンというのは何年後かの皆さんが使う普通のコンピュータなのです。つまり、スパコンとは、時間を節約する、速く計算するというものですけれども、時代的にも先取りしているということになります。研究というのは、先にできたものに当然、オリジナリティがありますので、例えば高精度の計算ができるということは、それによって先の、未来の研究ができるということかなと思っています。
先ほど、私の最初の専門が進化計算だということをお話ししましたけれども、今は人工知能全盛の時代で、計算機の中で人工的に進化をさせて、自動的に問題を解決するといったようなことも既に一部は可能になっているのです。例えば、航空機の設計など各種の設計で進化計算のアルゴリズムを用い、コンピュータの中で自動的に進化をさせて答えを出す、つまり新たな製品を作ってそれを社会に展開するということが、普通にできつつあります。
これは研究面でも同様で、人工知能がサポートしていくようになっています。人工知能だけではなくて、人工進化もですが、当然ながら人工知能より人工進化のほうが計算量は必要となります。なんとなくのイメージで分かるかもしれませんが、人工知能は1個の生物個体の中の話ですけれど、進化というのはそれが何千、何万、何億と集まったものです。当然ながら計算量が増えますし、将来的にもどんどん多く使う方向に進んでいきます。そのため、計算量があればあるほど、先のことができるということになります。そういった意味でも、いわゆる研究だけではなくてすべての面で、先ほどのトランスフォーメーションと言っていたのも、結局、進化なのです。進化を進めていくためのデジタル技術、それを加速するためのデジタル技術ということで、大学の競争力も、どれだけの計算リソースがあるかで決まっていきます。ITなどは、まさしくそうですよね。Googleなど、結局、計算リソースを持っているところが最後は勝つという構図になってきているのです。もちろん大学ですので、無尽蔵に計算機を買うわけにはいきませんけれども、スパコンのような、いわゆる大規模な情報基盤があるかないかが、大きな違いになってくるという点は、強調しておきたいと思います。
─ なるほど、色々な側面で本センターはとても大きい役割を果たしているということですね。
棟朝 そうですね。
─ 今回は貴重なお話を伺うことができました。ありがとうございます。
棟朝 ありがとうございました。
※1 mdx:9大学2研究所(北海道大学、東北大学、筑波大学、東京大学、国立情報学研究所、東京工業大学、名古屋大学、京都大学、大阪大学、九州大学および産業技術総合研究所)が連合し共同で運営している。
※2 情報環境推進本部の本部長は令和5年4月より総長が指名する理事をもって充てる。
———– 略歴 ————
棟朝 雅晴 Masaharu MUNETOMO
北海道大学情報基盤センター長
システムデザイン研究部門 教授
1996年北海道大学大学院工学研究科情報工学専攻博士後期課程修了。同年同大工学研究科助手。1998~1999年イリノイ大学アーバナシャンペーン校基礎工学部客員研究員。1999年北海道大学情報メディア教育研究総合センター助教授。2003年同大情報基盤センター助教授、2007年同准教授、2012年同教授。2013年情報基盤センター副センター長、2019年より同センター長となり現在に至る。並列分散処理、クラウドコンピューティング、進化計算等の人工進化、メタヒューリスティクス等の近似最適化アルゴリズムに関する研究に従事。本学情報環境推進本部において情報化推進室長、CIO補佐役を務め、本学の情報環境整備を主導している。これまでに情報処理学会北海道支部長・数理モデル化と問題解決研究会主査・論文誌「数理モデル化と応用」編集委員長、大学I CT推進協議会理事等を歴任し、現在は、進化計算学会会長、7大学情報基盤センタークラウドコンピューティング研究会主査。